As the joke goes, “there are 2 hard problems in computer science: cache invalidation, naming things, and off-by-one errors.” In this article, we’ll skip over why computer science only has one joke and instead focus on what makes cache invalidation “hard” and demonstrate how it can be solved in the context of a content management system.

First, though, let’s address the problem of “naming things” – the tongue-in-cheek reference in the joke above, which is itself a riff on Phil Karlton’s quote.
There are only two hard things in Computer Science: cache invalidation and naming things.
– Phil Karlton
Naming Things #
How we name things is important because choosing clear, meaningful and consistent names for a program’s variables, functions and classes can significantly improve its readability, maintainability and overall quality. Not doing so can lead to messy code that is hard to understand, especially in large, complex systems.
However, it is challenging to come up with good names that are descriptive, concise, and consistent with established naming conventions; that avoid abbreviations, acronyms, and overly generic names; and that use names that accurately reflect the intent and behaviour of what they represent. This is why naming conventions and style guides should be followed, or at least considered, whenever writing code as part of a larger system, such as Craft’s coding guidelines.

Cache Invalidation #
At its core, cache invalidation is the process of keeping cached data up-to-date with the original or source data. This is crucial for ensuring that users see the most recent and accurate information, with an acceptable amount of delay during which stale content may be visible.
Some form of caching is used in almost all systems, and for good reason. The performance benefits of caching can be huge, as observed in the Performance Testing Craft CMS with Blitz article that demonstrated how one Craft demo site was capped at 3 concurrent requests per second. Introducing “Blitz + Rewrites” as the caching strategy increased the number of concurrent requests per second to well over 700!
Cache invalidation, especially in the context of a content management system, is relevant in the following scenarios.
- When content is updated or deleted, all of the cached pages in which that content appeared must be invalidated.
- When new content is added, any cached pages that could potentially display that content must be invalidated.
- When content is scheduled for publishing or is set to expire at a future date and time, any cached pages that will be affected need to be invalidated at the appropriate date and time.
In order to enable each of the scenarios above, we need some way of maintaining relationships between content and the pages they are displayed on, or could potentially be displayed on, now or at some point in the future. So, no easy task!
The Challenges #
Creating a cache invalidation strategy to handle all of the above has the following requirements and associated challenges.
- Keeping track of what content is cached in which pages requires a storage system that is capable of representing and maintaining these relationships.
- Knowing what content changed at the exact time it changed requires being able to listen for triggers in core parts of the system.
- Figuring out which cached pages to invalidate based on changed content can be computationally expensive.
- Invalidating cached data can take time, especially in distributed systems.
- Scalability makes all of the above much, much harder.
Example Time #
Let’s look at a basic example using a cached “listing page” that lists a site’s 3 most recently published articles.
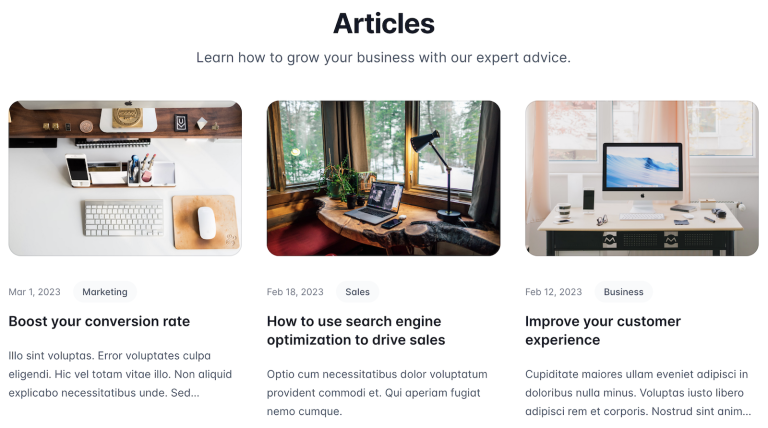
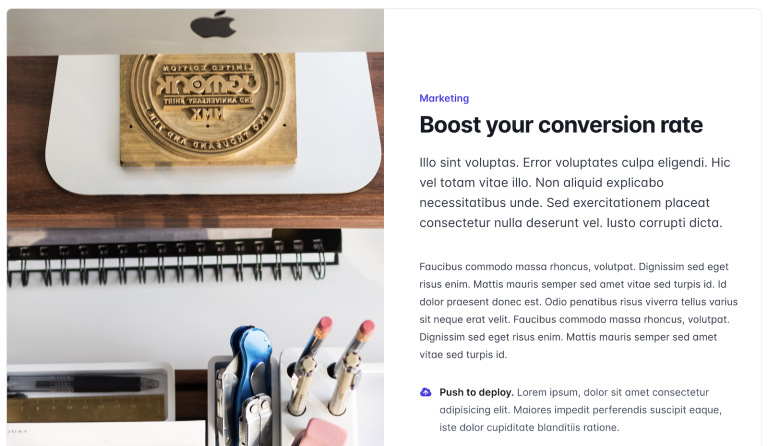
Each article also exists as a cached “detail page” in the site.
Scenario 1 #
Let’s start with scenario 1 above, in which an article’s content is changed. Our system needs to know that the article’s content is output on both the listing page as well as the article detail page in order to be able to invalidate those cached pages. Similarly, when an article is deleted, both the listing page, as well as the (now deleted) article detail page must be invalidated.
Invalidating the cache will generally consist of clearing the cached values in whatever cache store is used, whether a file system, a database or a distributed key-value store such as Redis. But the system may choose to mark the cached values as expired instead of clearing them immediately. This allows it to regenerate or replace the stale cache with freshly cached pages at some point in future, helping to avoid pages ever being in a non-cached state. This may be desirable for high-traffic sites in which requests to the origin server should be avoided as much as possible.
Scenario 2 #
Let’s move on to scenario 2 above, in which a new article is published. This time, our system needs to understand that the listing page outputs the three most recently published articles. In other words, the articles are ordered by publish date descending and are limited to three.
In this instance, the cached page will need to be invalidated if and only if the new article’s publish date is more recent than the oldest article that currently appears (“Feb 12, 2023”). So the system needs to keep track of not only which articles are output, but also what criteria determine which articles are output on which pages.
Scenario 3 #
Scenario 3 is the real kicker. We expect an article that is scheduled for publishing at a future date and time to appear on the listing page at that exact date and time. However, our system doesn’t detect any explicit changes that could trigger an invalidation, and so the only way of detecting whether an article’s future publish (or expiration) date has passed is to manually check on a recurring basis.
This is generally achieved by creating a cron job set to run every couple of minutes. But it also means that our system needs to track every article’s future publish and expiration date and time, and that there will inevitably be delays in articles going live or expiring. A small amount of delay is acceptable for most sites but may not be for time-sensitive sites such as those that display to-the-minute breaking news.

Solving the Problem #
Solving the problem and challenges that the scenarios above present is possible only with a system that provides us with a mechanism for detecting changes. In the case of Craft CMS, the codebase is littered with useful events that are triggered each time certain actions take place, including when elements containing content are changed. We can listen for these events using modules or plugins and perform actions each time they’re triggered.
Blitz is a popular performance plugin that has deep integration with Craft CMS, which it leverages to solve the problem of cache invalidation as efficiently as possible. Interestingly, how it achieves this is not a black box but a set of strategies that can be explained and learned from.
1. Tracking Elements #
Blitz tracks which elements are used on which pages (by unique URI). This allows it to know which cached pages to invalidate when an element is changed (scenario 1 above). It gets even smarter, though, by additionally tracking which specific custom fields of which elements are used per page (as of version 4.4).
2. Tracking Element Queries #
Blitz also tracks which element queries are executed on which pages. This allows it to know which cached pages may have to be invalidated when a new element is created (scenario 2 above). It gets smart here, too, by additionally tracking which element attributes and custom fields are used in each element query (as of version 4.4).
3. Tracking Post and Expiry Times #
For each element in the CMS, Blitz tracks its “post” and “expiry” date and time, provided they are in the future. This allows it to know which exact cached pages to invalidate when an element becomes published or unpublished based on the current date and time (scenario 3 above).
4. Listening for Element Changes #
All of the above is made possible by listening for changes made to elements in the CMS. Blitz detects not only whether an element has been updated but whether its content has actually changed. Additionally, Blitz tracks what specific attributes or custom fields were changed (as of version 4.4).
5. Determining what to Invalidate #
This is where the “magic” happens. Based on all of the information that Blitz has previously collected, it is able to very accurately determine which cached pages must be invalidated based on the specific content (and specific fields) that changed in the system.
Imagine, for example, that the most recent article’s title in the example above was renamed from “Boost your conversion rate” to “Increase your conversion rate”. Blitz would detect the change to the title and determine that every cached page that displays the article’s title should be invalidated. On the other hand, if only the article’s body content was changed, Blitz would determine that only pages that display the body content (in this case, the detail page but not the listing page) should be invalidated.
Similarly, if a new article was created with a post date later than “Mar 1, 2023”, Blitz would determine that every page that could potentially display an article published on that date, in our case, the listing page, should be invalidated. Whereas if the post date was “Feb 1, 2023”, Blitz would be able to determine that no pages should be invalidated since the article is too old to appear in the listing of the three latest articles.
Blitz 4.4 added tracking of which custom fields are output per element per page, as well as which attributes and custom fields are changed on each element save. This dramatically reduces the number of cached pages that must be invalidated when content changes, as well as the number of element queries that must be executed during the cache refresh process.
And so we end up with all of our scenarios accounted for. Blitz achieves this by addressing each of the challenges above in the following ways.
- Leveraging relational database tables to keep track of the relationships between elements, element queries, attributes, fields and pages (URIs).
- Listening for element save events triggered within the CMS and detecting what specific content changed.
- Determining which cached pages to invalidate based on the stored relationships and by executing only the element queries that can be affected by the content changes that took place.
- Invalidating cached pages by either clearing them immediately or marking them as expired and optionally regenerating those pages in a background task.
- Scalability is still not completely solved – if your site consists of tens of thousands of pages and millions of relationships, then it will suffer if not optimised. Fortunately, following a few best practices can greatly help reduce the types of issues that can arise at large scale.